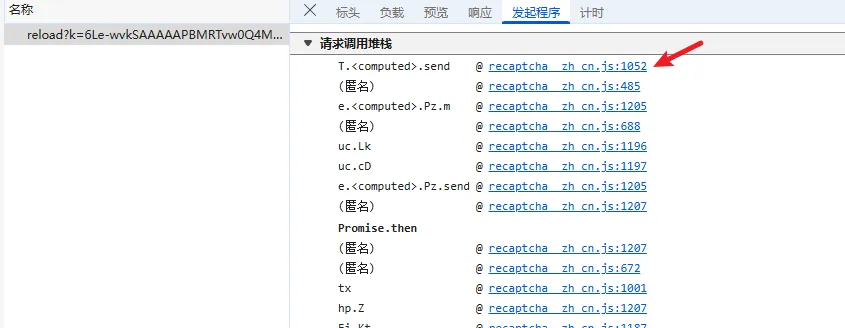
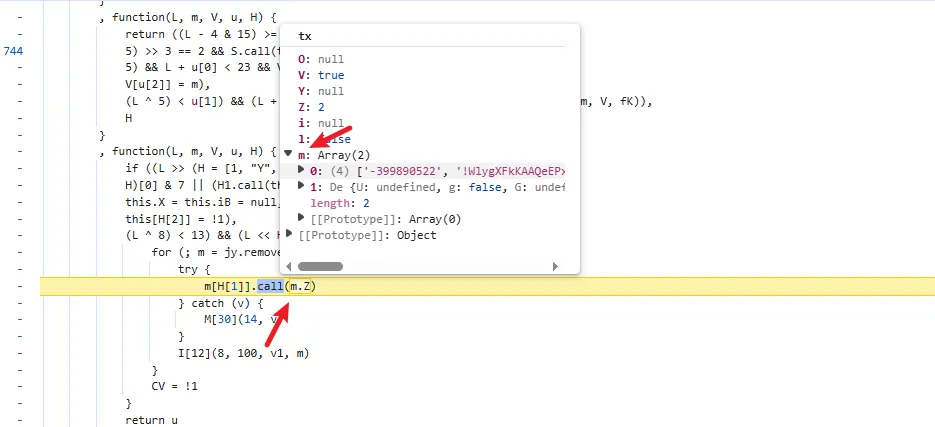
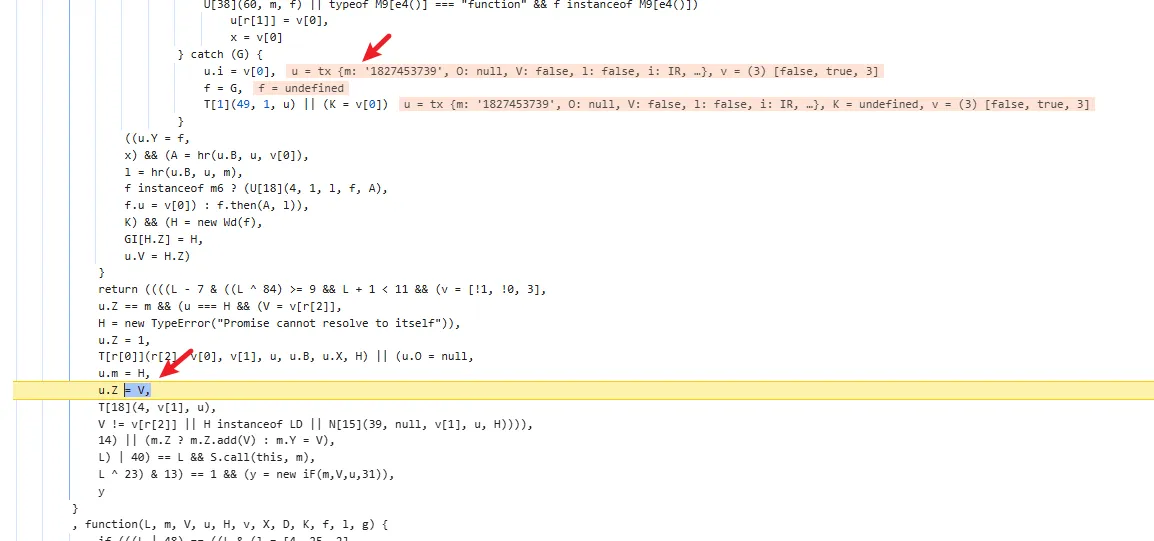
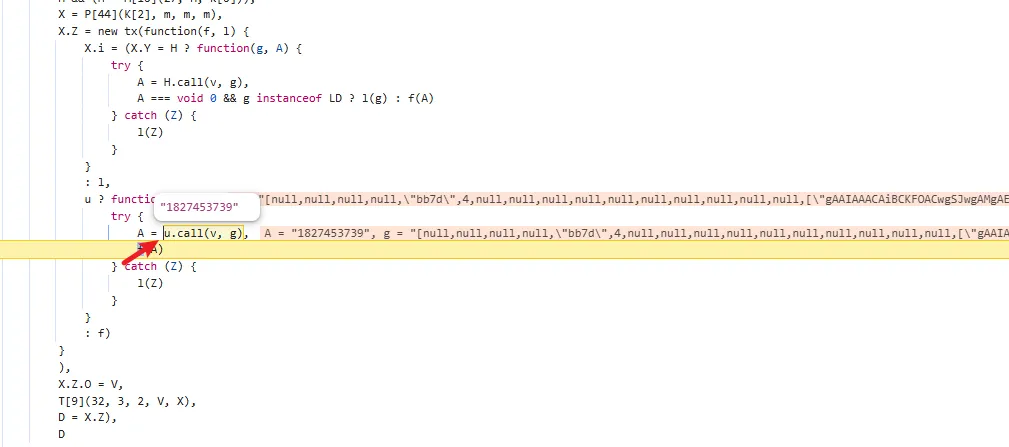
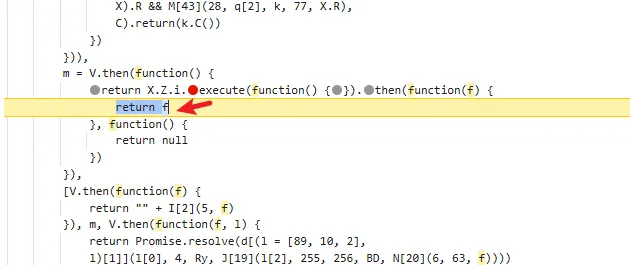
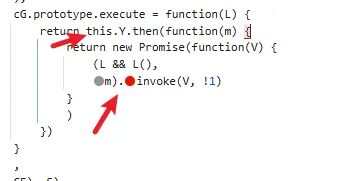
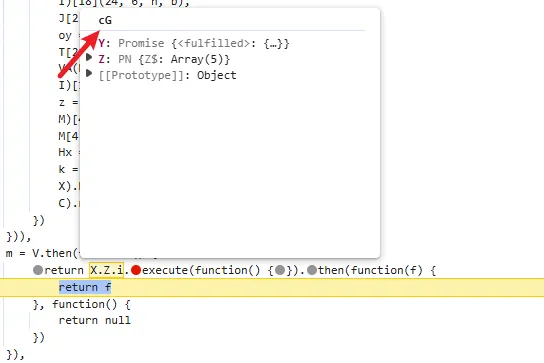
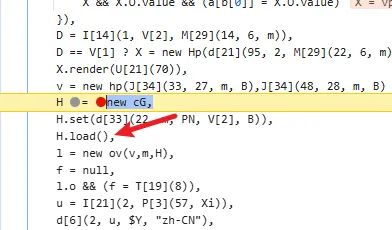
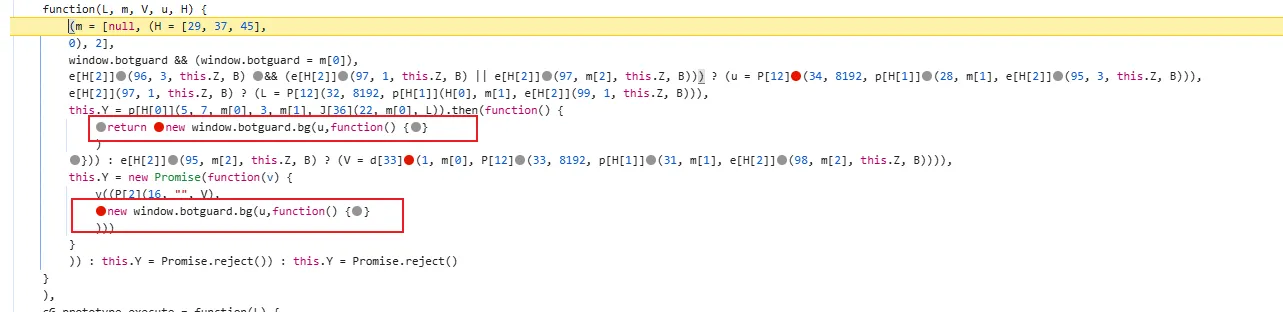
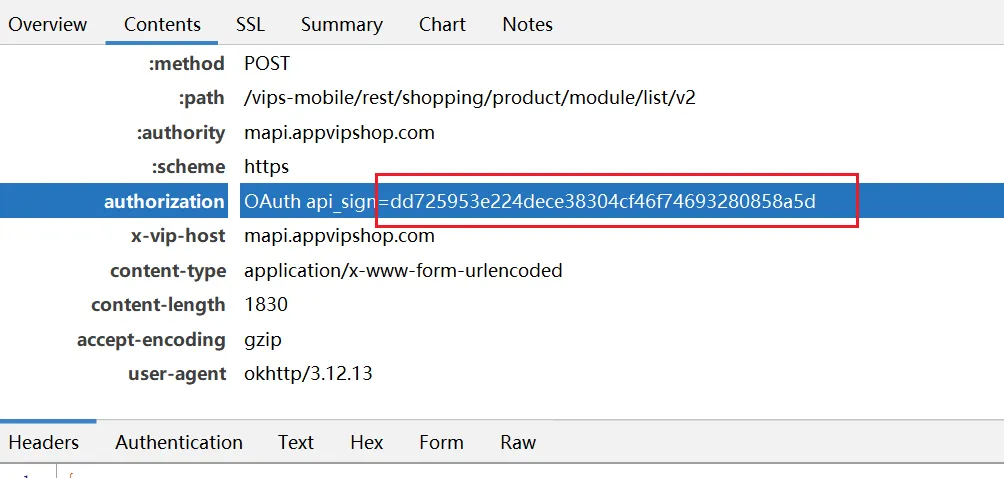
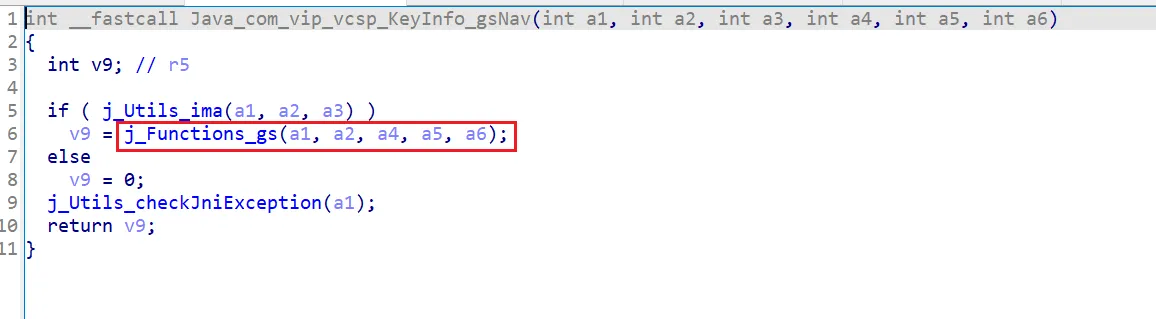
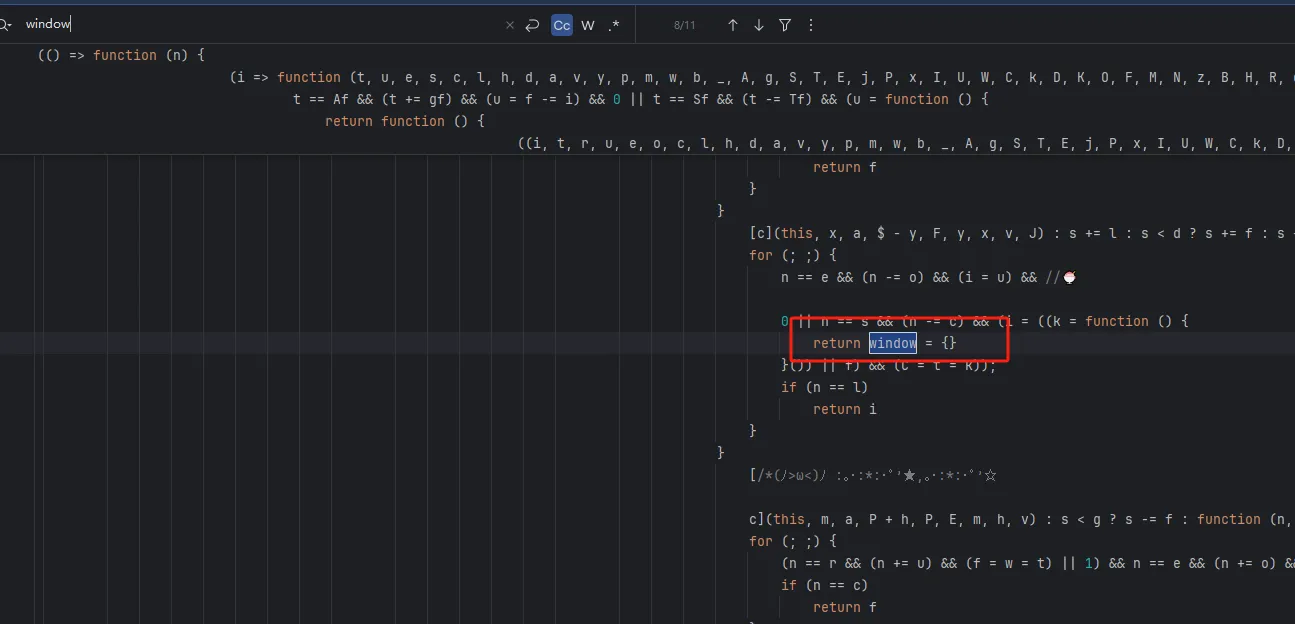
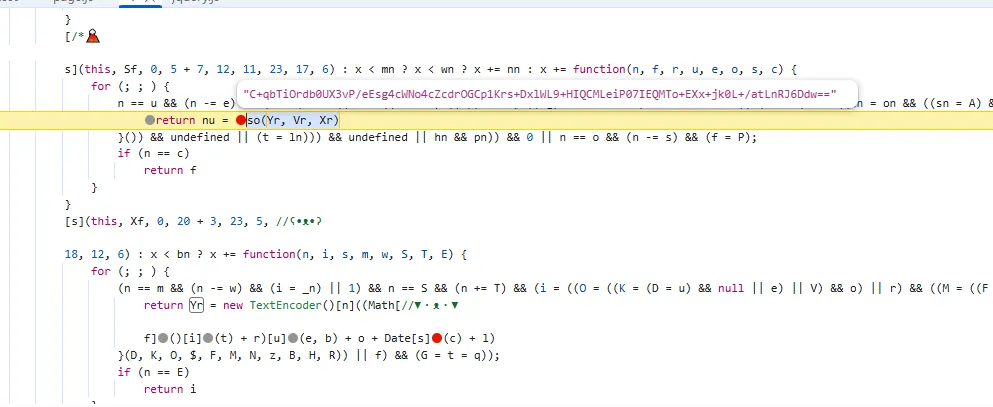
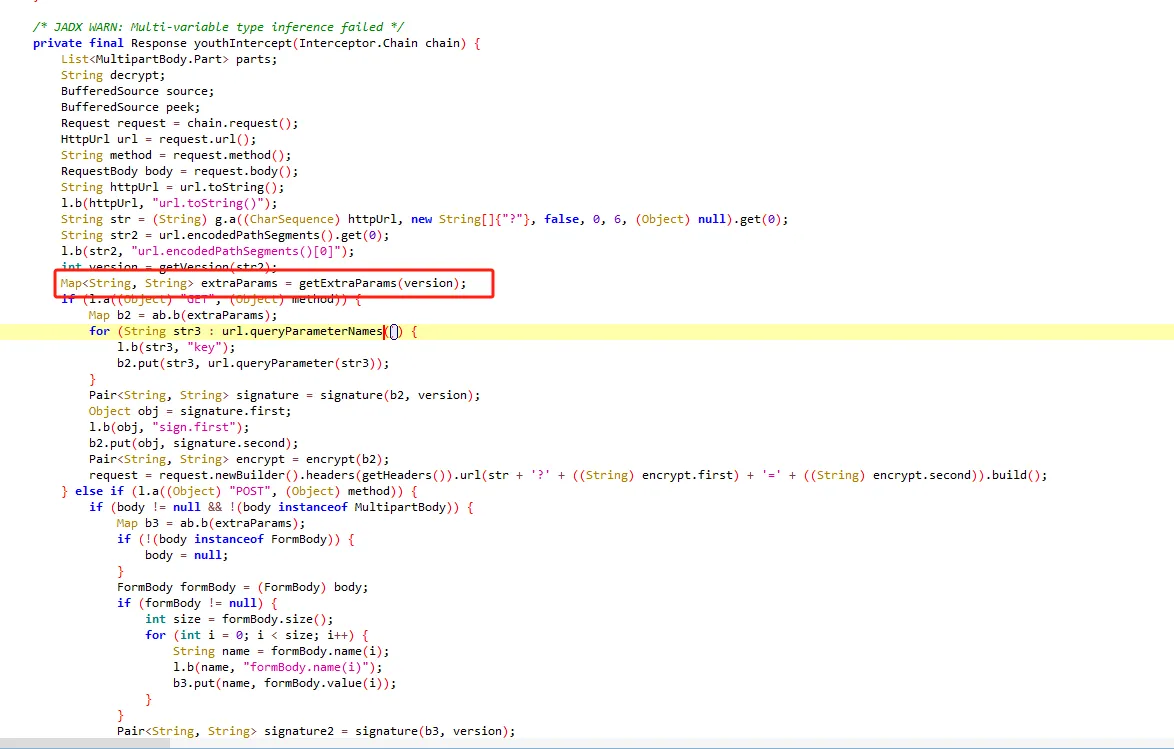
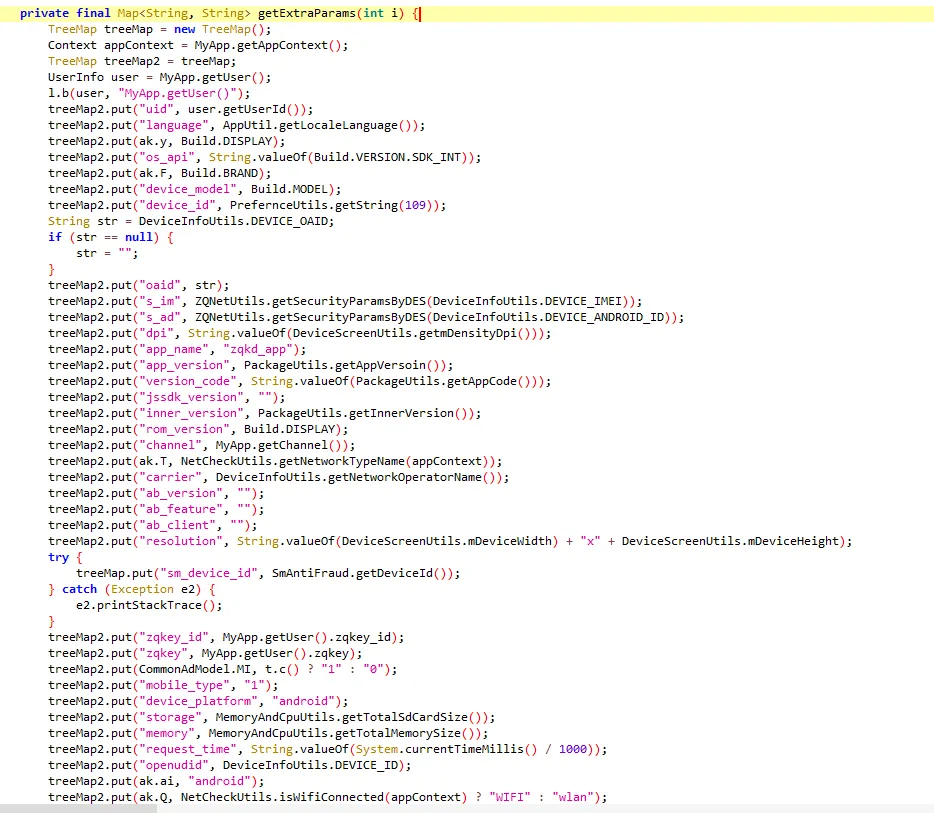
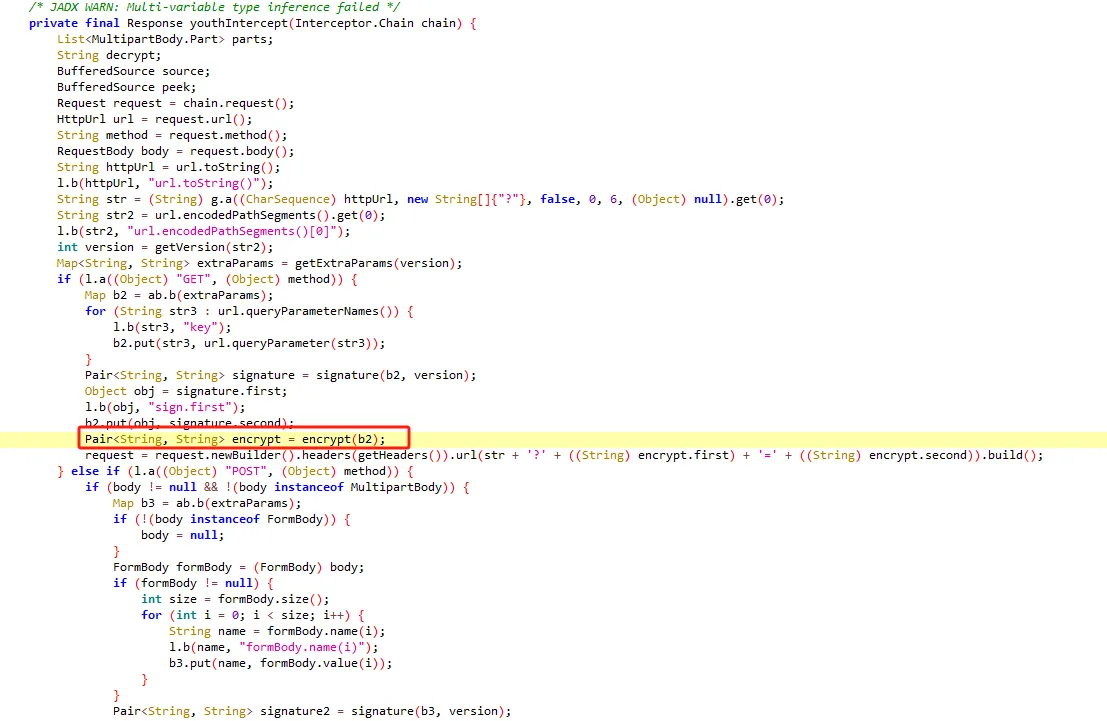
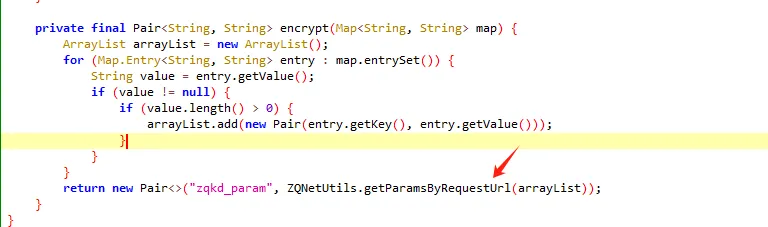
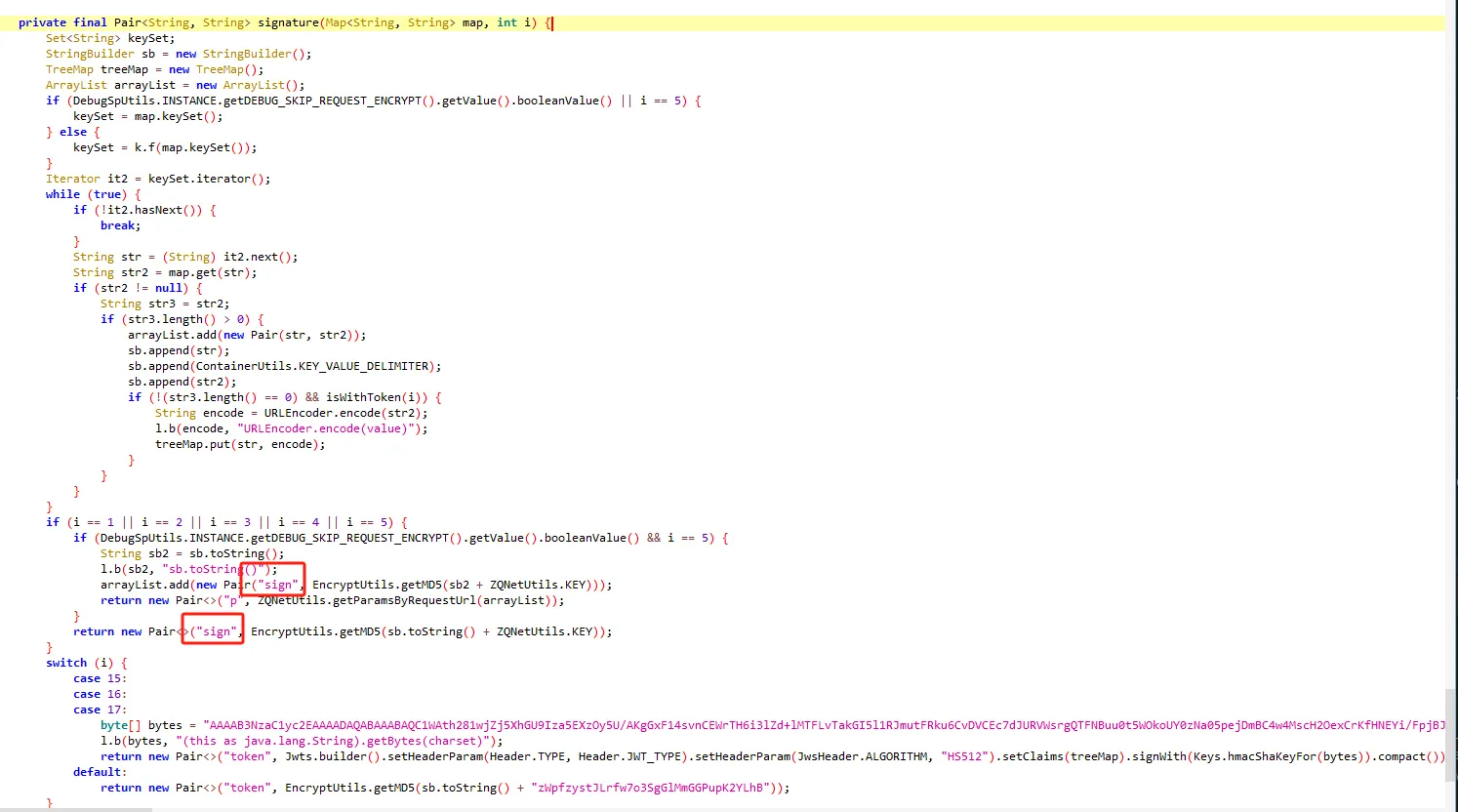
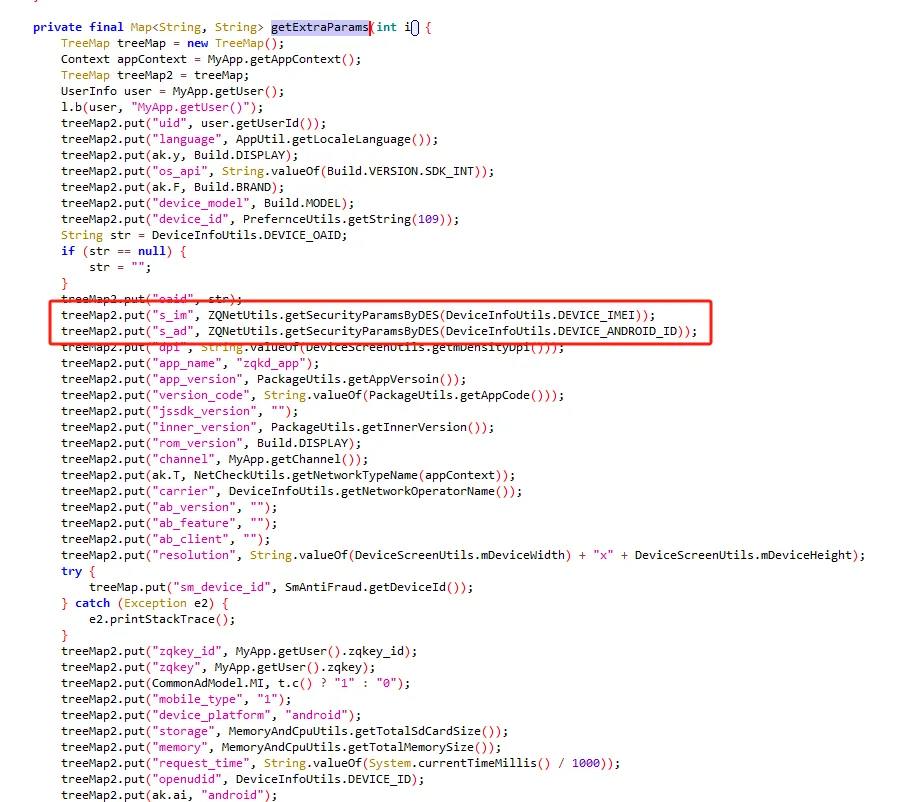
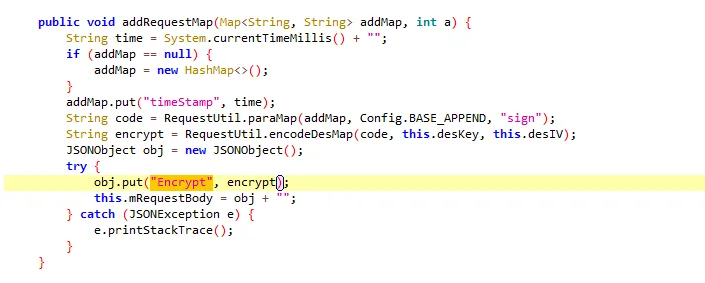
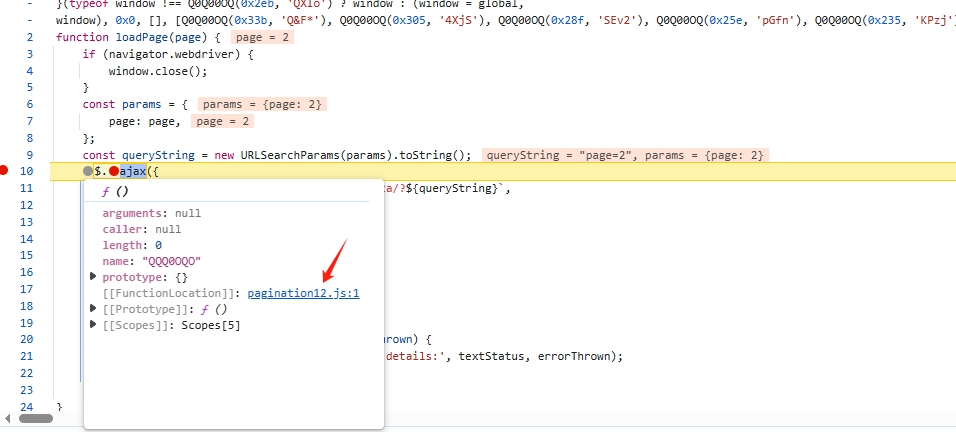
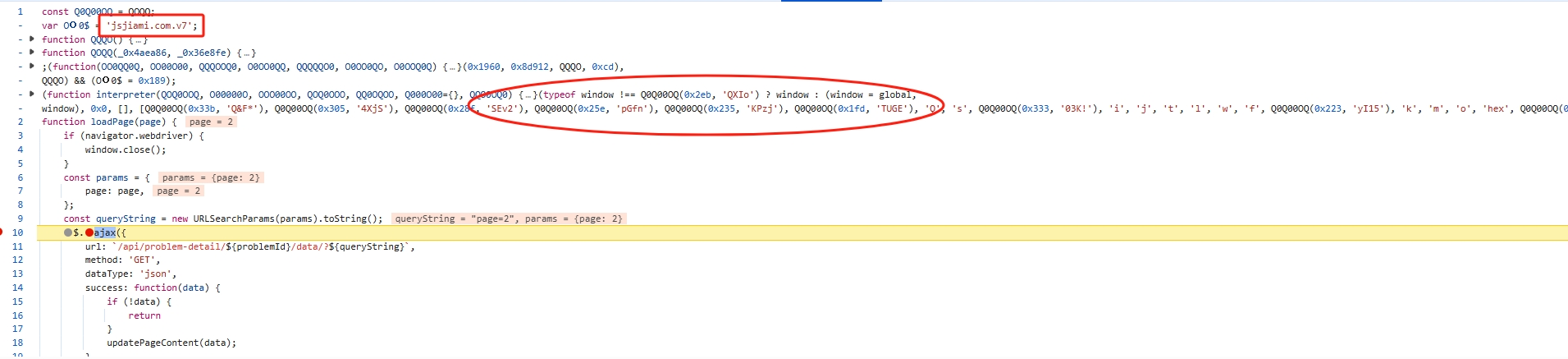
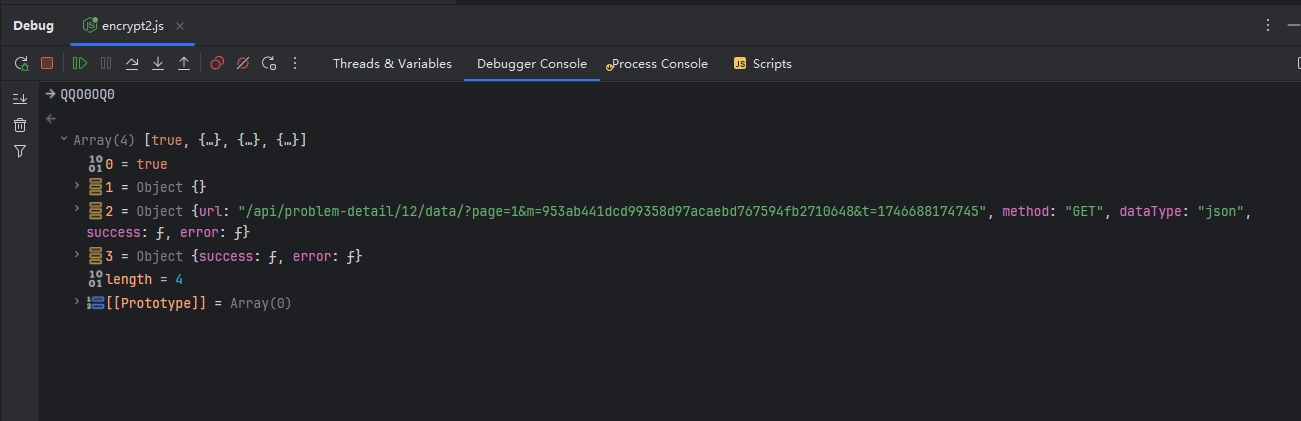
functionhookStrBuilder() { var stringBuilderClass = Java.use("java.lang.StringBuilder"); stringBuilderClass.toString.implementation = function () { var res = this.toString.apply(this, arguments) console.log('tostring is called ', res) return res } }
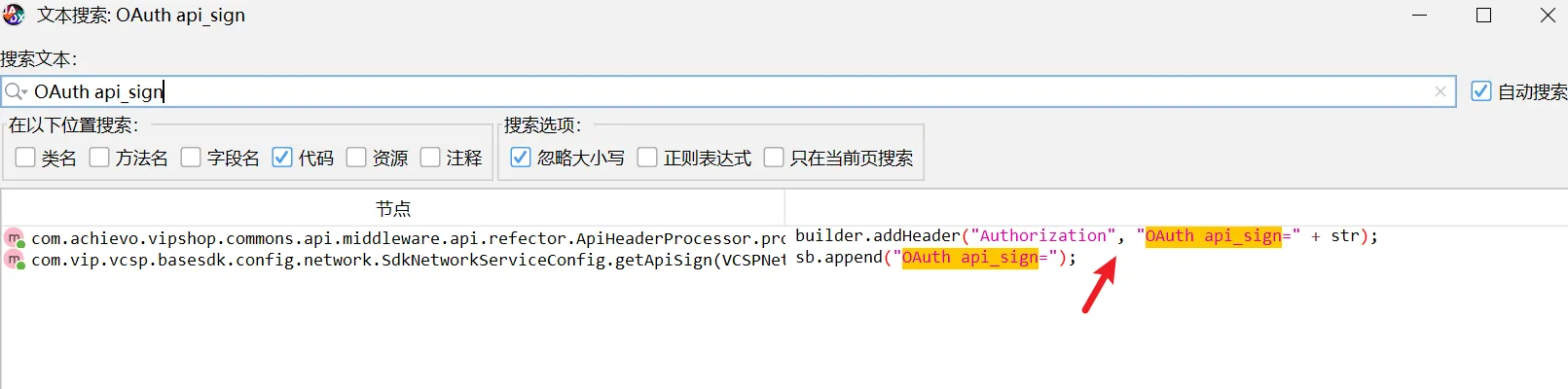
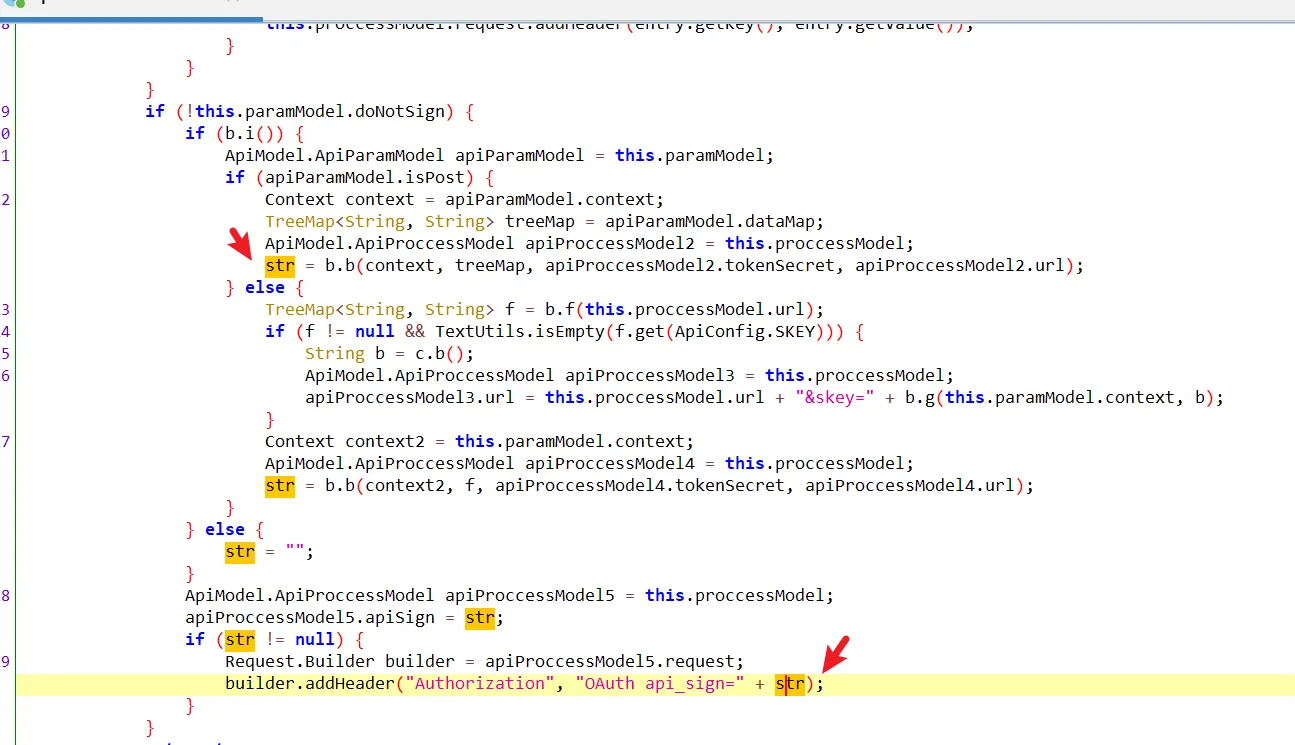
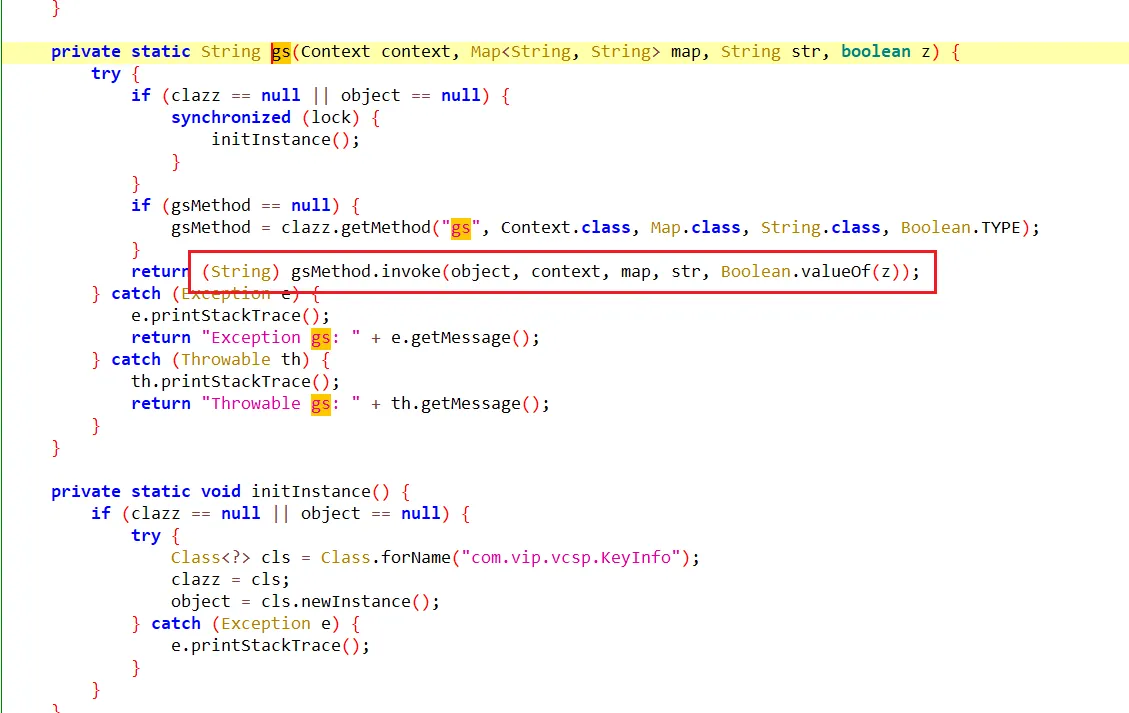
通过hook StringBuilder的方式发现了有用的信息
1
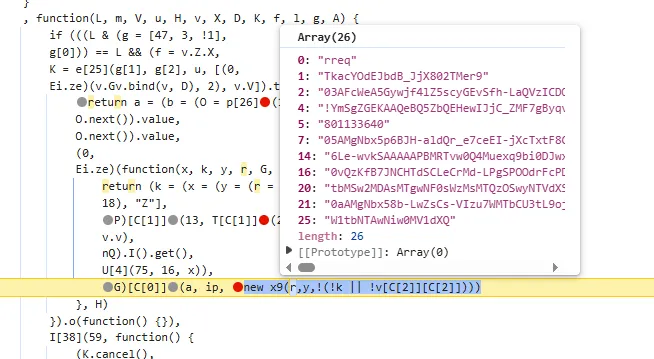
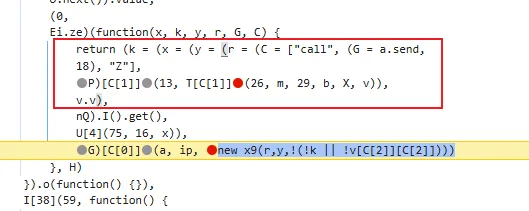
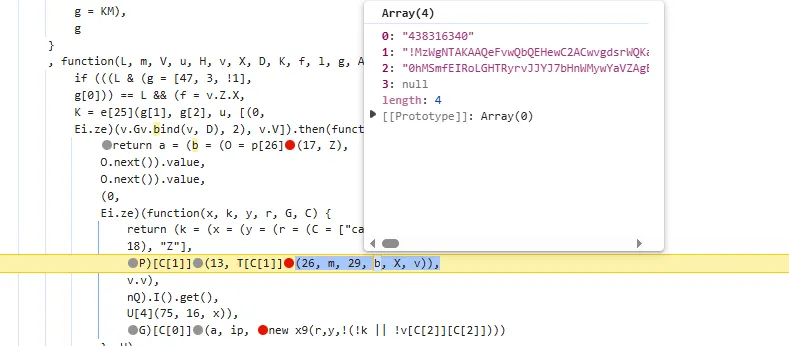
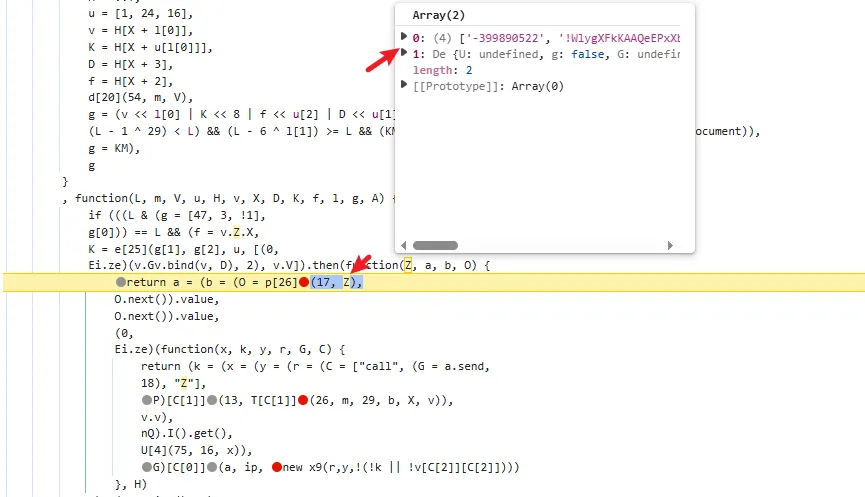
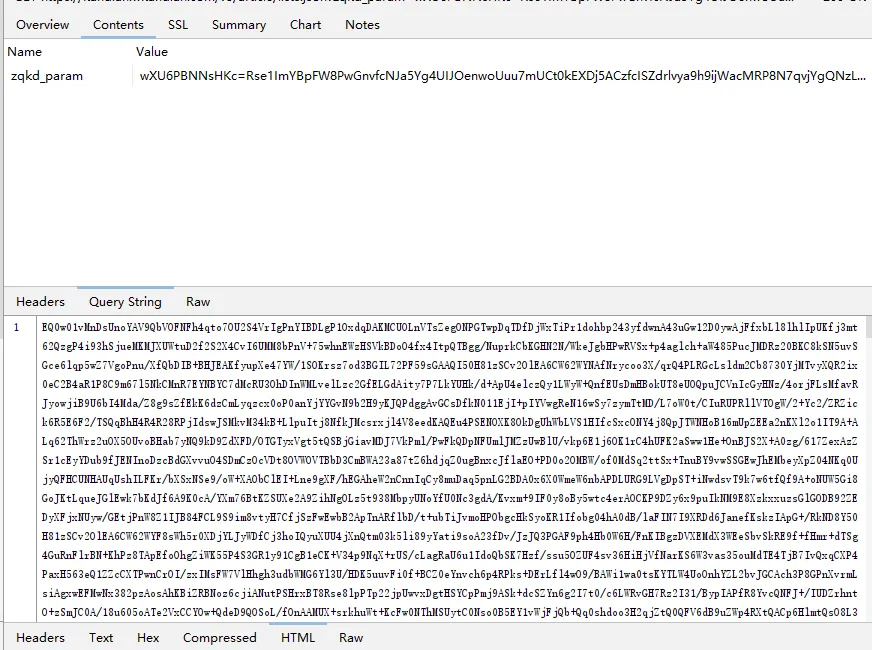
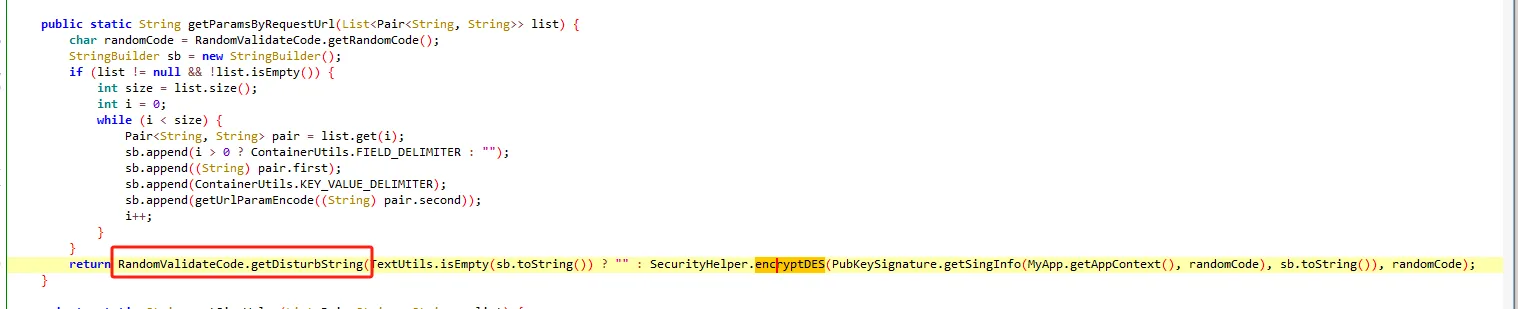
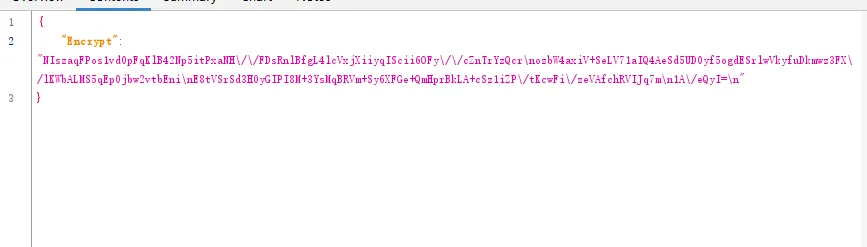
tostring is called /v3/article/lists.json?zqkd_param=wXU6PBNNsHKc=Rse1ImYBpFW8PwGnvfcNJa5Yg4UIJOenwoUuu7mUCt0kEXDj5ACzfcISZdrlvya9h9ijWacMRP8N7qvjYgQNzL45veAD9SZlcNH7QJiW-AyOu-HKB7OjeSRZjvPBBbhhbTTyw1eCHnMU1uJ5rY0g4DsUz7lEmml-PRkpa-F1BmjpS2U6j9kmZC3j04W40ZV6Btru9WfGSEtyo55F50BGtVWw4gDRYBrqDVK3R4yTIlg4WcMjD_UWWS_LqaLpL-LgBIdx8PpPfoAqmkM6cOo-DdD-Sb5IZNA_-aRQJVT_RoscdZPNjM8u5Si_x_MSUwe16vJMr7rCd3_D5i9lNAQDlqAGfEkcgPQkWll25ietvQOJqZgTdv9L0Ko85-u7yPOwliw2rStygqCQXqOZ4j0m2UBpRoMQNJyGNO1tuK6zl-iqsCg-G7ChY15A6rAZhJzxBQ-6UTv_BLRrpRs-bQ2oV_eQif_2zDq4BvFsJ36xpfTrmu0eoclncG-Qmx8kyakYqk2Q_9TKO517I3G3P5hIfK4pPb0GDzgZH2fQ9VtkaWWMdHyCqcxlKRBd0lvQBqE8Gs7LivC1bVg1iCZNXQhiDUzjEUOjopcpoWullznXXRsje7qK87rQpKFKP85n24ppAbmBrT5kgnGkd8s9AvBM5yK-yMq3sDyhU-kJIgDDnKFIZM6dK9tFZYNuDH3SUw0CZ607P0CUz1X-CPmPD3AyHfFJyjUe_wDCwxmbsweN_TnUeP57IA4g-HHwOnEcBwS3LBOthXVepwDCjn5rFk4Jy8-XUAou-gRO7B6o-Tpb3kZcXH7T3ur0C150l-swLgYq1Wliep2WZLLrNAXSMPxzUflN5g5ATLTXCcAPYEmaO6f43GHGActJlY967F23PWQh7bG510CfNtnpHHa1UgfYQgeTy4el3pGuxB4YpN2YCFl074efcPCQU3LzwiMsbAQHOS3jwhfumesz-JGJrsfyxgLPr31HBmsswFZpDtjoVpUWFM8J7wHcdO1zdvlnACoRdeIYUTNibXUpRf80ONyt1PXalttPuHJpFgcR5EIXdSNVhAj4yNZEZTa0ot2TE7cxWsbNlP0U7UNRhxMAifcMbENf85nUtxrFdGDaMeQg8V_KN61_FELDhiI0Q_N8LhcWyc18Eyr-r153Gs6JF3uA02HUkKKRM5nzMJrywO5syHBvnSb80Wg2tjIiKJvwYE0ZY7bOHiv6Gbr6fX-hgWMTJ4777mClRdCJ5p0Q4eAvRskgkNwmavuw6lw1QwQwpVepPGl4GpbmZMTm6QXBrGMqcdUMrDuzKCgMoAZV7yhL8gk=
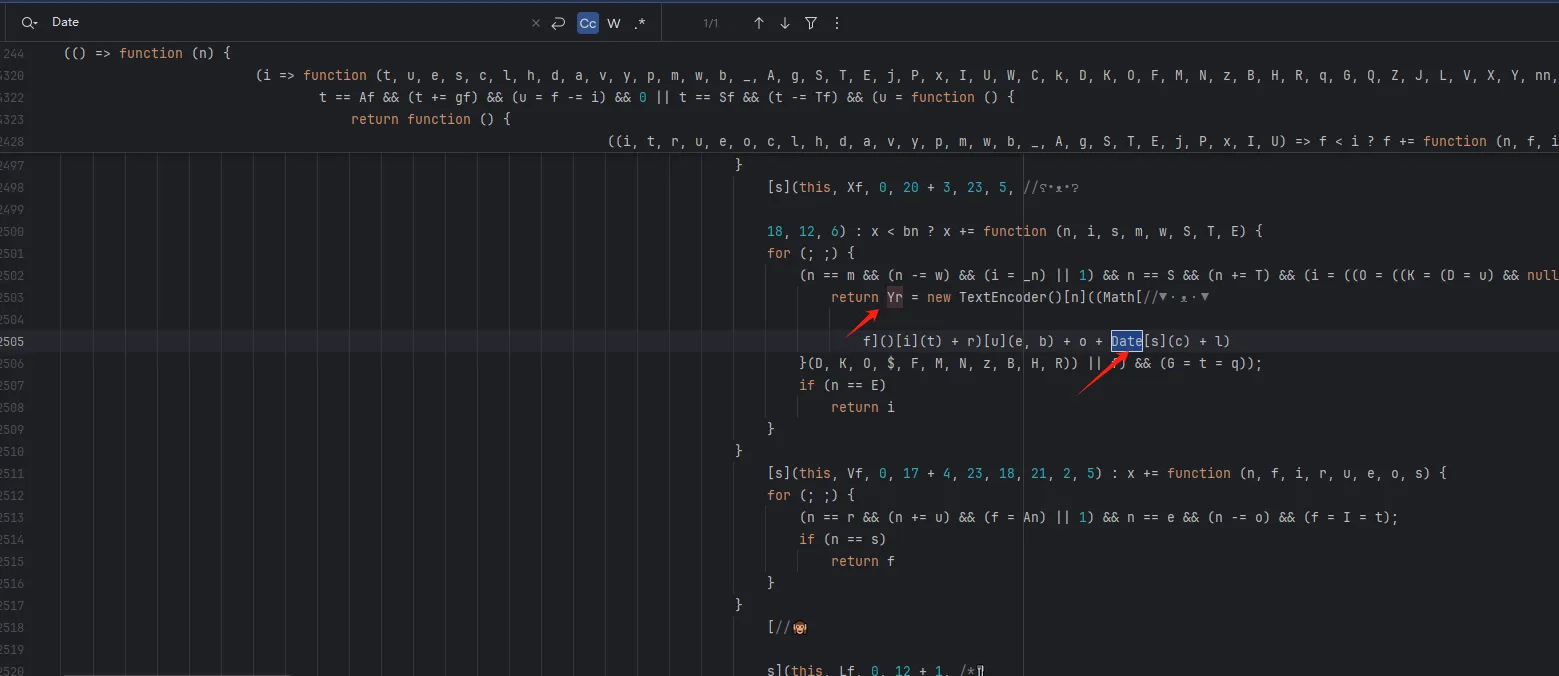
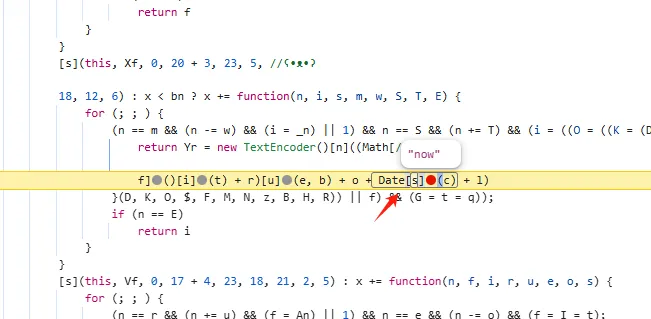
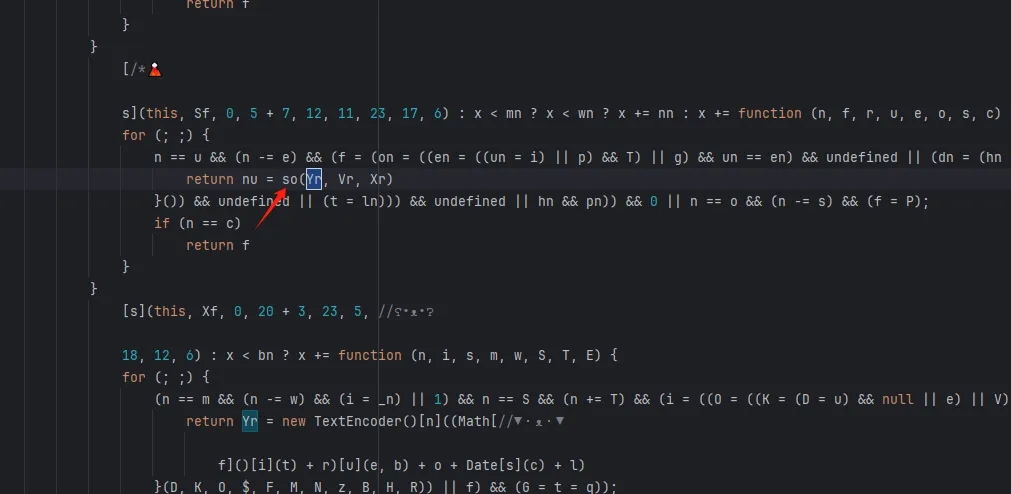
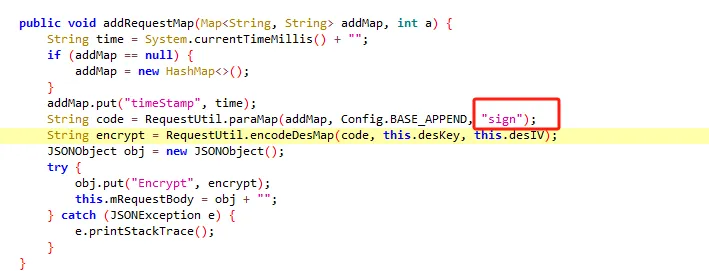
functionhookStrBuilder() { // 获取 StringBuilder 类并定义需要 Hook 的方法名 var stringBuilderClass = Java.use("java.lang.StringBuilder"); stringBuilderClass.toString.implementation = function () { var res = this.toString.apply(this, arguments) if (res.includes('zqkd_param')) { showStacks() console.log('tostring is called ', res) } // console.log('tostring is called ', res) return res } }
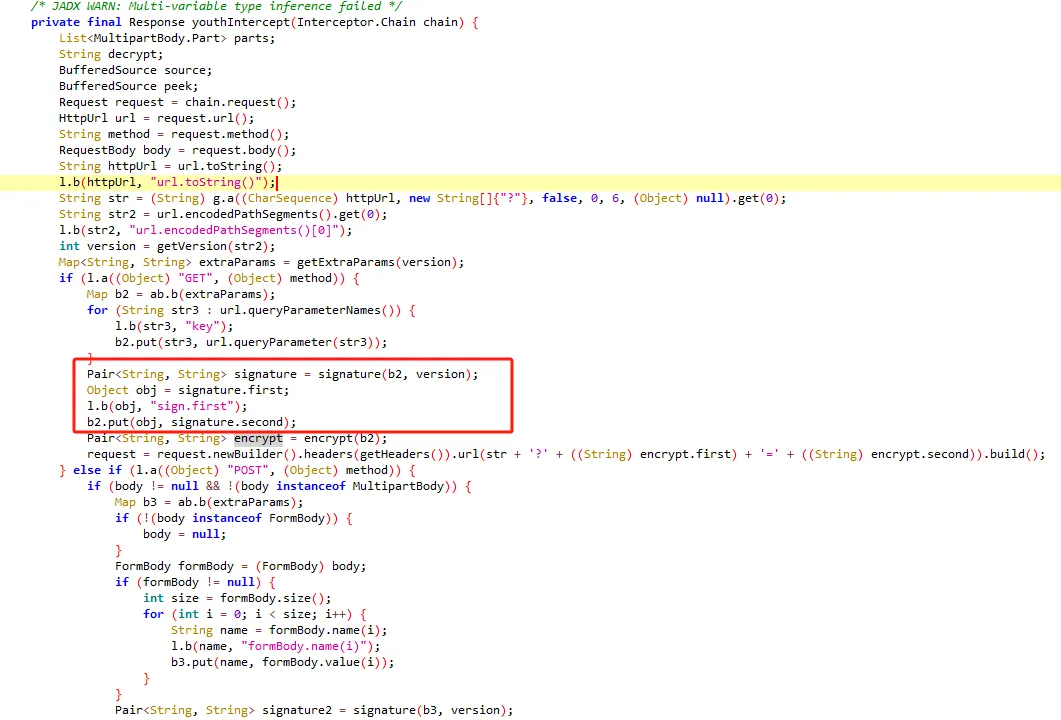
tostring is called https://kandian.wkandian.com/v3/article/lists.json?zqkd_param=wXU6PBNNsHKc=Rse1ImYBpFW8PwGnvfcNJa5Yg4UIJOenwoUuu7mUCt0kEXDj5ACzfcISZdrlvya9h9ijWacMRP8N7qvjYgQNzL45veAD9SZlcNH7QJiW-AyOu-HKB7OjeSRZjvPBBbhhbTTyw1eCHnMU1uJ5rY0g4DsUz7lEmml-PRkpa-F1BmjpS2U6j9kmZC3j04W40ZV6Btru9WfGSEtyo55F50BGtVWw4gDRYBrqDVK3R4yTIlg4WcMjD_UWWS_LqaLpL-LgBIdx8PpPfoAqmkM6cOo-DdD-Sb5IZNA_-aRQJVT_RoscdZPNjM8u5Si_x_MSUwe16vJMr7rCd3_D5i9lNAQDlqAGfEkcgPQkWll25ietvQOJqZgTdv9L0Ko85-u7yPOwliw2rStygqCQXqOZ4j0m2UBpRoMQNJyGNO1tuK6zl-iqsCg-G7ChY15A6rAZhJzxBQ-6UTv_BLRrpRs-bQ2oV_eQif_2zDq4BvFsJ36xpfTrmu0eoclncG-Qmx8kyakYqk2Q_9TKO517I3G3P5hIfK4pPb0GDzgZH2fQ9VtkaWWMdHyCqcxlKRBd0lvQBqE8Gs7LivC1bVg1iCZNXQhiDUzjEUOjopcpoWullznXXRsje7qK87rQpKFKP85n24ppAbmBrT5kgnGkd8s9AvBM5yK-yMq3sDyhU-kJIgDDnKFIZM6dK9tFZYNuDH3SUw0CZ607P0CUz1X-CPmPD3AyHfFJyjUe_wDCwxmbsweN_TnUeP57IA4g-HHwOnEcBwS3LBOthXVepwDCjn5rFk4Jy8-XUAou-gRO7B6o-Tpb3kZcXH7T3ur0C150l-swLgYq1Wliep2WZLLrNAXSMPxzUflN5g5ATLTXCcAPYEmaO6f43GHGActJlY967F23PWQh7bG510CfNtnpHHa1UgfYQgeTy4el3pGuxB4YpN2YCFl074efcPCQU3LzwiMsbAQHOS3jwhfumesz-JGJrsfyxgLPr31HBmsswFZpDtjoVpUWFM8J7wHcdO1zdvlnACoRdeIYUTNibXUpRf80ONyt1PXalttPuHJpFgcR5EIXdSNVhAj4yNZEZTa0ot2TE7cxWsbNlP0U7UNRhxMAifcMbENf85nUtxrFdGDaMeQg8V_KN61_FELDhiI0Q_N8LhcWyc18Eyr-r153Gs6JF3uA02HUkKKRM5nzMJrywO5syHBvnSb80Wg2tjIiKJvwYE0ZY7bOHiv6Gbr6fX-hgWMTJ4777mClRdCJ5p0Q4eAvRskgkNwmavuw6lw1QwQwpVepPGl4GpbmZMTm6QXBrGMqcdUMrDuzKCgMoAZV7yhL8gk= java.lang.Throwable at java.lang.StringBuilder.toString(Native Method) at okhttp3.internal.http.RequestLine.requestPath(RequestLine.java:62) at okhttp3.internal.http.RequestLine.get(RequestLine.java:40) at okhttp3.internal.http1.Http1Codec.writeRequestHeaders(Http1Codec.java:128) at okhttp3.internal.http.CallServerInterceptor.intercept(CallServerInterceptor.java:50) at okhttp3.internal.http.RealInterceptorChain.proceed(RealInterceptorChain.java:147) at okhttp3.internal.connection.ConnectInterceptor.intercept(ConnectInterceptor.java:45) at okhttp3.internal.http.RealInterceptorChain.proceed(RealInterceptorChain.java:147) at okhttp3.internal.http.RealInterceptorChain.proceed(RealInterceptorChain.java:121) at okhttp3.internal.cache.CacheInterceptor.intercept(CacheInterceptor.java:93) at okhttp3.internal.http.RealInterceptorChain.proceed(RealInterceptorChain.java:147) at okhttp3.internal.http.RealInterceptorChain.proceed(RealInterceptorChain.java:121) at okhttp3.internal.http.BridgeInterceptor.intercept(BridgeInterceptor.java:93) at okhttp3.internal.http.RealInterceptorChain.proceed(RealInterceptorChain.java:147) at okhttp3.internal.http.RetryAndFollowUpInterceptor.intercept(RetryAndFollowUpInterceptor.java:126) at okhttp3.internal.http.RealInterceptorChain.proceed(RealInterceptorChain.java:147) at okhttp3.internal.http.RealInterceptorChain.proceed(RealInterceptorChain.java:121) at cn.youth.news.network.api.YouthNetworkInterceptor.youthIntercept(YouthNetworkInterceptor.kt:246) at cn.youth.news.network.api.YouthNetworkInterceptor.intercept(YouthNetworkInterceptor.kt:62) at okhttp3.internal.http.RealInterceptorChain.proceed(RealInterceptorChain.java:147) at okhttp3.internal.http.RealInterceptorChain.proceed(RealInterceptorChain.java:121) at cn.youth.news.network.api.LogInterceptor.intercept(LogInterceptor.java:219) at okhttp3.internal.http.RealInterceptorChain.proceed(RealInterceptorChain.java:147) at okhttp3.internal.http.RealInterceptorChain.proceed(RealInterceptorChain.java:121) at okhttp3.RealCall.getResponseWithInterceptorChain(RealCall.java:250) at okhttp3.RealCall.execute(RealCall.java:93) at retrofit2.l.a(OkHttpCall.java:186) at retrofit2.a.a.c.b(CallExecuteObservable.java:45) at io.reactivex.m.a(Observable.java:12267) at retrofit2.a.a.a.b(BodyObservable.java:34) at io.reactivex.m.a(Observable.java:12267) at io.reactivex.internal.e.e.an$b.run(ObservableSubscribeOn.java:96) at io.reactivex.internal.g.l.call(ScheduledDirectTask.java:38) at io.reactivex.internal.g.l.call(ScheduledDirectTask.java:26) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1167) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:641) at java.lang.Thread.run(Thread.java:764) at com.blankj.utilcode.util.z$e$1.run(ThreadUtils.java:1150)
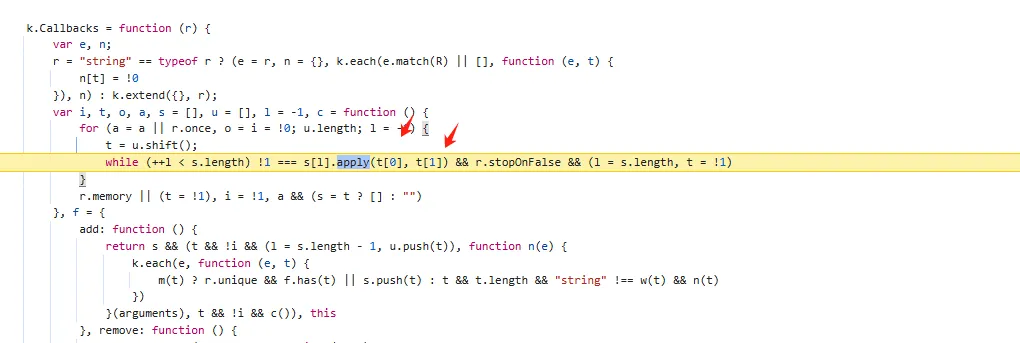
functionbytesToString(arr) { if (typeof arr === 'string') { return arr; } var str = '', _arr = arr; for (var i = 0; i < _arr.length; i++) { var one = _arr[i].toString(2), v = one.match(/^1+?(?=0)/); if (v && one.length == 8) { var bytesLength = v[0].length; var store = _arr[i].toString(2).slice(7 - bytesLength); for (var st = 1; st < bytesLength; st++) { store += _arr[st + i].toString(2).slice(2); } str += String.fromCharCode(parseInt(store, 2)); i += bytesLength - 1; } else { str += String.fromCharCode(_arr[i]); } } return str; }
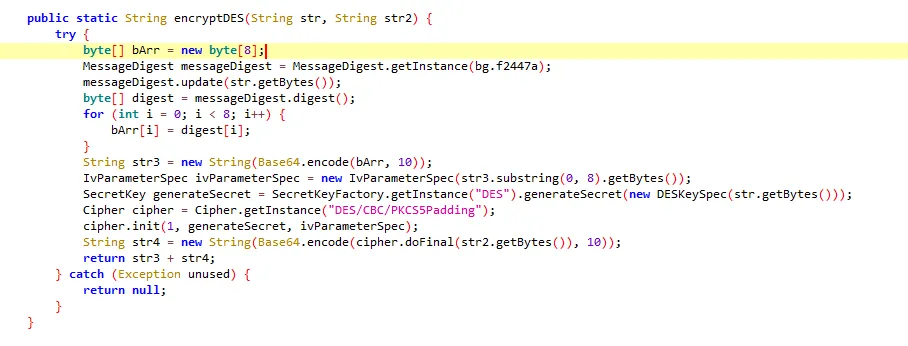
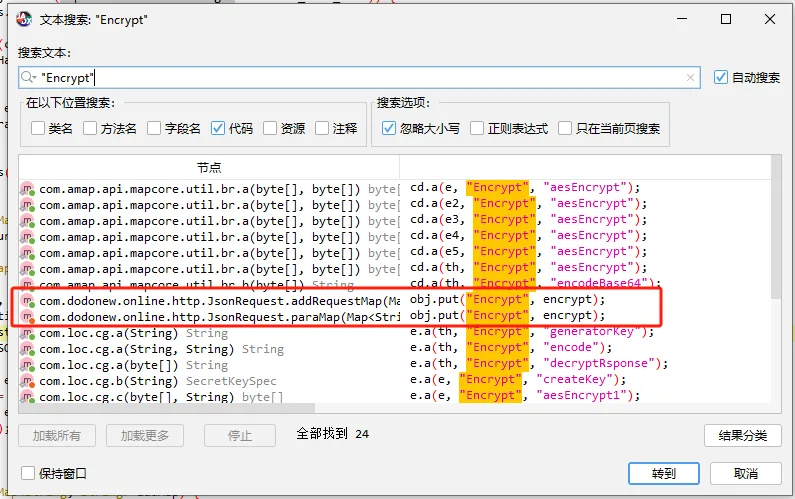
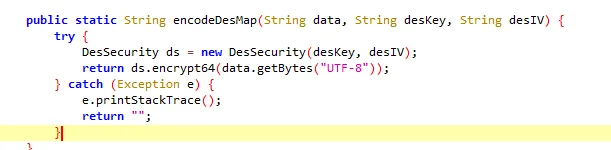
functionhookMd5() { letEncryptUtils = Java.use("cn.youth.news.utils.EncryptUtils"); EncryptUtils["getMD5"].overload('[B').implementation = function (bArr) { console.log(`EncryptUtils.getMD5 is called: bArr=${bytesToString(bArr)}`); let result = this["getMD5"](bArr); console.log(`EncryptUtils.getMD5 result=${result}`); return result; }; }
import base64 from urllib.parse import urlencode import hashlib import json from Crypto.Cipher import DES from Crypto.Util.Padding import pad, unpad from Crypto.Hash import MD5