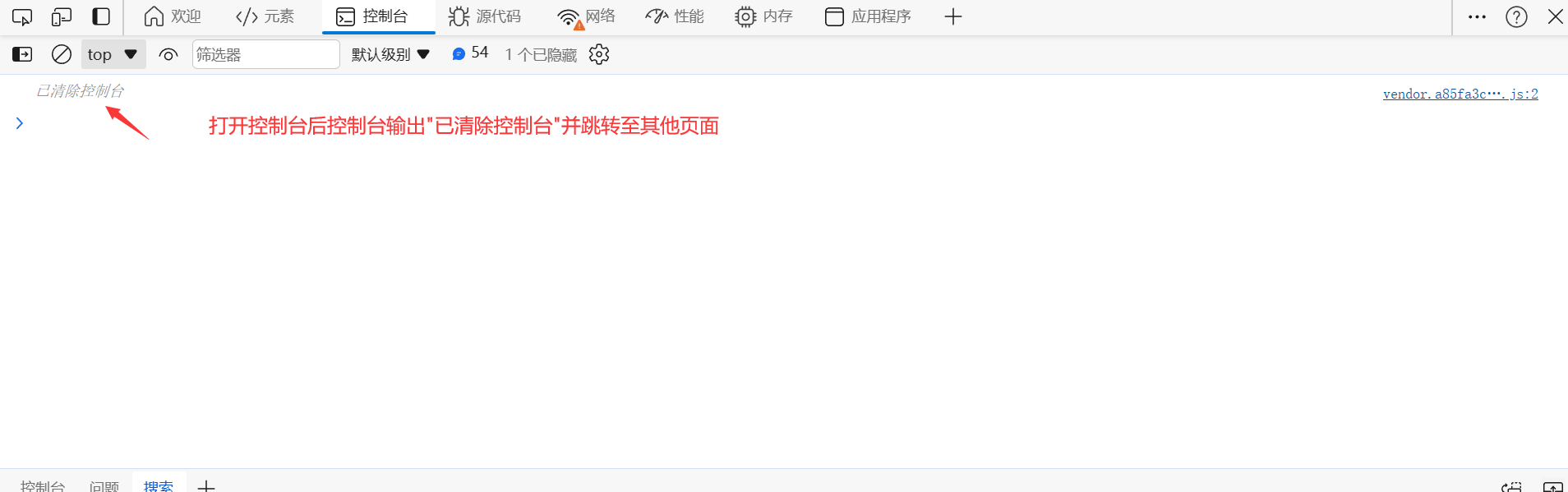
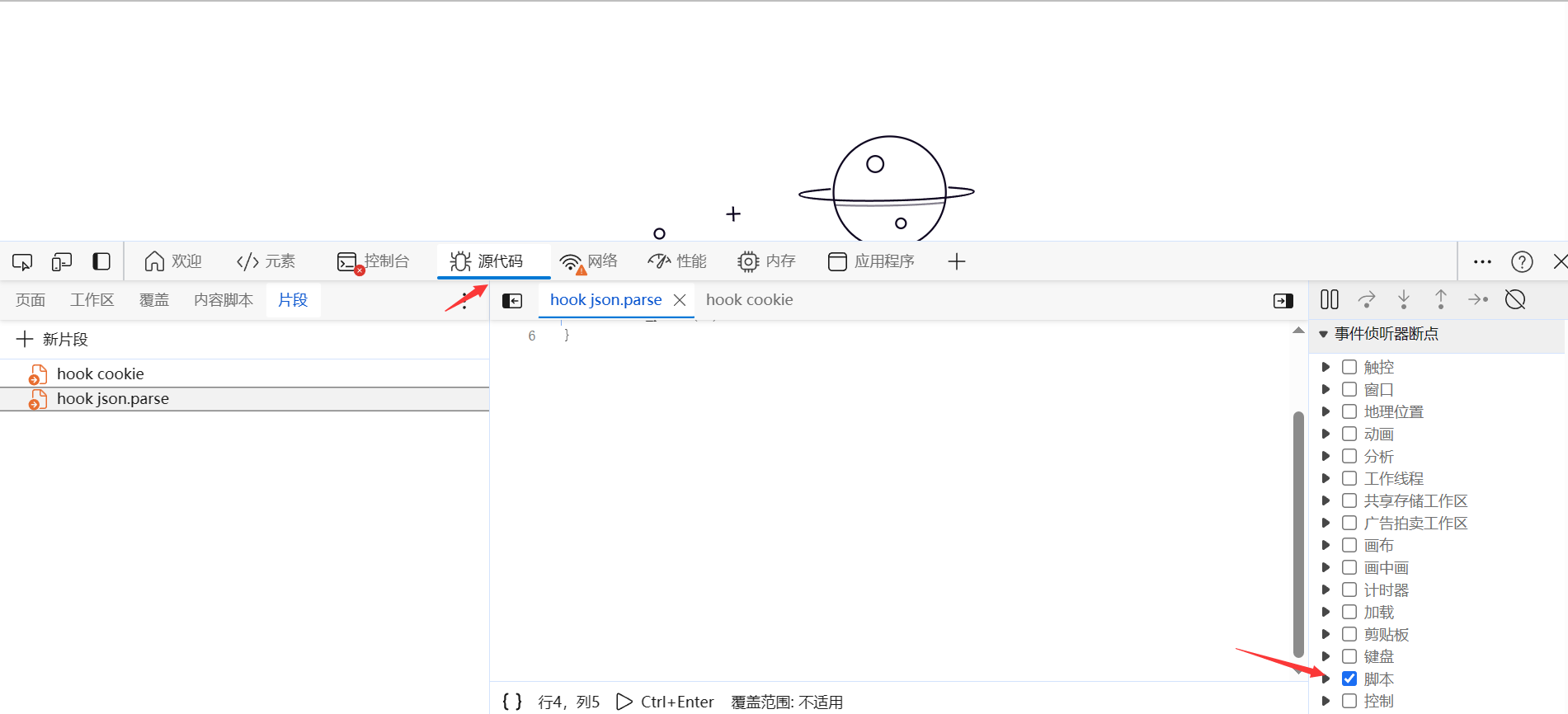
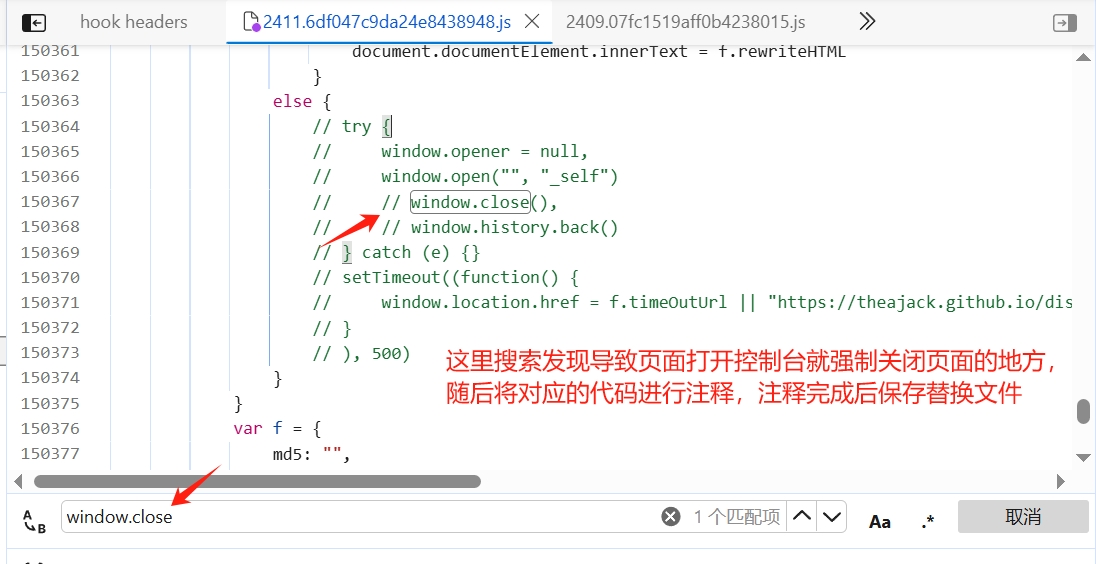
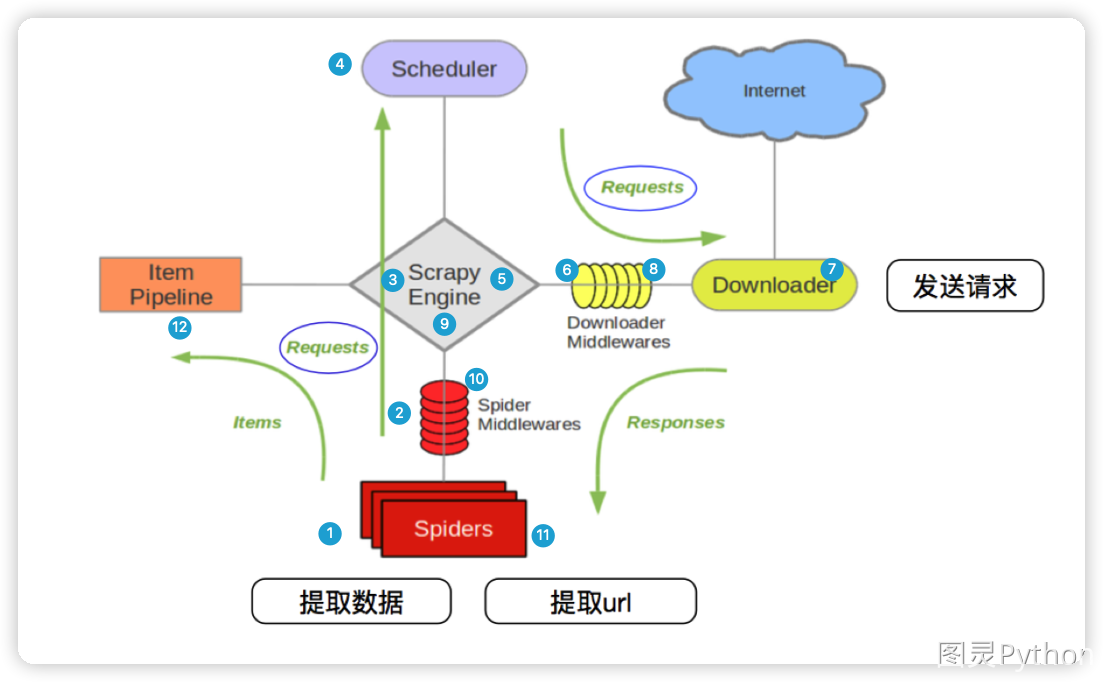
1、爬虫子模块的使用 1.1.通过parse函数返回字典数据 通过(scrapy genspider 爬虫名称 目标网址)命令可以创建我们的爬虫子模块,爬虫子模块的作用主要是负责定义白名单、起始请求的url地址、以及对response对象的数据清洗。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def parse (self, response: HtmlResponse, **kwargs ): a_list = response.xpath("//div[@class='rank-list']/a" ) for a_temp in a_list: rank_number = a_temp.xpath('./div[@class="badge"]/text()' ).extract_first() img_url = a_temp.xpath('./img/@src' ).extract_first() title = a_temp.xpath('./div[@class="content"]/div[@class="title"]/text()' ).extract_first() desc = a_temp.xpath('./div[@class="content"]/div[@class="desc"]/text()' ).extract_first() play_number = a_temp.xpath('.//div[@class="info-item"][1]/span/text()' ).extract_first() yield { 'type' : 'info' , 'rank_number' : rank_number, 'img_url' : img_url, 'title' : title, 'desc' : desc, 'play_number' : play_number }
注意: yield能够传递的对象只有: BaseItem、Request、dict、None
1.2.通过parse函数返回request对象 在实际爬虫过程中我们可能需要先提取到一个url,再通过url再次发起请求去获取对应的数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 def parse (self, response: HtmlResponse, **kwargs ): a_list = response.xpath("//div[@class='rank-list']/a" ) for a_temp in a_list: rank_number = a_temp.xpath('./div[@class="badge"]/text()' ).extract_first() img_url = a_temp.xpath('./img/@src' ).extract_first() title = a_temp.xpath('./div[@class="content"]/div[@class="title"]/text()' ).extract_first() desc = a_temp.xpath('./div[@class="content"]/div[@class="desc"]/text()' ).extract_first() play_number = a_temp.xpath('.//div[@class="info-item"][1]/span/text()' ).extract_first() yield { 'rank_number' : rank_number, 'img_url' : img_url, 'title' : title, 'desc' : desc, 'play_number' : play_number } """ callback: 指定解析函数 cb_kwargs: 如果解析方法中存在形参,则可以通过cb_kwargs传递,传递参数的类型必须是字典,字典中的key必须与解析方法中的形参名称保持一致 """ yield scrapy.Request(img_url, callback=self.parse_imgage, cb_kwargs={'image_name' : title}) def parse_imgage (self, response, image_name ): yield { 'image_name' : image_name.replace('|' , '' ) + '.png' , 'image_content' : response.body }
在上一个例子中我们通过yield返回了一个request对象,通过callback定义了一个回调函数,这个回调函数主要负责去对该request请求的响应结果进行解析,通过cb_kwargs将回调函数需要的参数值进行传递。注意: cb_kwargs接收的是一个字典,并且字典中的key名称必须与回调函数的形参名称保持一致。
1.3.start_request方法的使用 假设我们需要访问多页的数据或者访问的是一个api接口,如果将所有的请求都放在start_urls列表中就会显得很臃肿,并且可扩展性不高,那么我们可以在爬虫子类中重写start_requests方法来定义我们请求的规则
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Top250Spider (scrapy.Spider): """ 如果使用spider类默认的请求方式,则不会对重复请求进行过滤 会重复请求相同的url """ name = "top250" allowed_domains = ["movie.douban.com" ] start_urls = ["http://movie.douban.com/top250" , "http://movie.douban.com/top250" ] def start_requests (self ): url = 'https://movie.douban.com/top250?start={}&filter=' for page in range (10 ): yield scrapy.Request(url.format (page * 25 ), dont_filter=False )
当我们重写了start_requests方法时,爬虫启动后则不会去遍历start_urls列表构造request请求,而是直接进入start_requests方法中构造我们自己定义的请求规则。scrapy.Request方法中有一个参数dont_filter,这个参数主要的作用是在请求url时不会重复请求相同的url
1.4.发送post请求 1.4.1.发送表单数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class JcInfoSpider (scrapy.Spider): name = "jc_info" def start_requests (self ): url = 'http://www.xxx.com.cn/new/disclosure' for page in range (1 , 11 ): data = { "column" : "szse_latest" , "pageNum" : str (page), "pageSize" : "30" , "sortName" : "" , "sortType" : "" , "clusterFlag" : "true" } yield scrapy.FormRequest(url=url, formdata=data)
1.4.2.发送json数据 1 2 3 4 5 6 7 8 9 10 11 12 13 from scrapy.http import JsonRequestclass NetEaseInfoSpider (scrapy.Spider): name = "netease_info" def start_requests (self ): url = 'https://xxx.com/api/hr163/position/queryPage' for page in range (1 , 10 ): payload = { "currentPage" : page, "pageSize" : 10 } yield JsonRequest(url, data=payload)
发送json数据的时候需要导入JsonRequest方法
2、下载中间件的使用 下载中间件位于middlewares.py文件中,当引擎将request对象交给下载器时会先经过下载中间件,下载中间件可以给request添加请求头或者代理等,自定义的下载中间件需要在setting文件中激活。
2.1.下载中间件给request对象添加请求头 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class UserAgentDownloaderMiddleware : USER_AGENTS_LIST = [ "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)" , "Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)" , "Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)" , "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)" , "Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6" , "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1" , "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0" , "Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5" ] def process_request (self, request, spider ): print ('下载中间件的process_request方法被调用...' ) user_agent = random.choice(self.USER_AGENTS_LIST) request.headers['User-Agent' ] = user_agent """ 如果返回None, 表示当前的request提交下一个权重低的process_request。 如果传递到最后一个process_request,则传递给下载器进行下载。 如果返回的是response对象则不再请求,把response对象直接交给引擎 """
2.2.下载中间件给request对象添加代理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 class ProxyDownloaderMiddleware : def process_request (self, request, spider ): print ('免费代理中间件 - 代理设置...' ) request.meta['proxy' ] = 'http://117.0.0.1:7890' print (request.meta['proxy' ]) def process_response (self, request, response, spider ): print ('免费中间件 - 代理检测...' ) if response.status != 200 : request.dont_filter = True return request return response
3、管道的使用 管道用于接收spider解析好的数据,通过管道可以将解析好的数据进行保存,使用管道前需要将管在setting文件中进行激活
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 class TxWorkFilePipeline : def open_spider (self, spider ): if spider.name == 'tx_work_info' : self.file_obj = open ('tx_work_info.txt' , 'a' , encoding='utf-8' ) def process_item (self, item, spider ): """ 在当前方法中可以对item进行数据判断,如果不符合数据要求,一般有两种方式来处理: 1. 扔掉 抛出一个异常中断当前管道,阻止item通过return传递给下一个管道 2. 修复 在当前方法中编辑修复代码逻辑并使用return将修复的数据传递给下一个item 注意: 当前方法如果存在return item则将item数据传递给下一个item 如果return不存在则将None传递给下一个item """ if spider.name == 'tx_work_info' : self.file_obj.write(json.dumps(item, ensure_ascii=False , indent=4 ) + '\n' ) print ('数据写入成功:' , item) return item def close_spider (self, spider ): if spider.name == 'tx_work_info' : self.file_obj.close() class TxWorkMongoPipeline : def open_spider (self, spider ): if spider.name == 'tx_work_info' : self.mongo_client = pymongo.MongoClient(host='192.168.198.130' ) self.collection = self.mongo_client['py_spider' ]['tx_work_info' ] def process_item (self, item, spider ): if spider.name == 'tx_work_info' : self.collection.insert_one(item) print ('数据写入mongodb成功:' , item) return item def close_spider (self, spider ): if spider.name == 'tx_work_info' : self.mongo_client.close()
上述例子中自定义了2个管道类,这两个管道类分别将数据存储在不同的地方,需要注意的是如果某一个管道类需要先执行完再去执行下一个管道,则需要在settings文件中将需要先执行的管道类权重低于后执行管道类的权重
4.settings文件的参数详解 是否开启robots.txt验证
请求延迟
1 2 3 4 DEFAULT_REQUEST_HEADERS = { "Accept" : "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8" , "Accept-Language" : "en" , }
设置默认的请求头信息
1 2 3 SPIDER_MIDDLEWARES = { "TxWork.middlewares.SeleniumDownloaderMiddleware" : 543 , }
爬虫中间件的配置信息
1 2 3 DOWNLOADER_MIDDLEWARES = { "TxWork.middlewares.SeleniumDownloaderMiddleware" : 543 , }
下载中间件的配置信息,若要使用下载中间件就需要在settings文件中将下载中间件的注释放开
1 2 3 4 ITEM_PIPELINES = { "TxWork.pipelines.TxWorkFilePipeline" : 300 , "TxWork.pipelines.TxWorkMongoPipeline" : 301 }
管道配置信息,若要使用管道则需要在settings文件中手动开启
1 2 3 EXTENSIONS = { "scrapy.extensions.telnet.TelnetConsole" : None , }
拓展类的配置信息,如果自定义了一些工具类想要使用,则需要在settings文件中启用
5、items的使用 items类主要用于进行字段的校验,如果将数据保存进数据库,数据库表字段名称和我们最终解析返回字典数据中的key不匹配时会导致数据插入失败,我们可以通过在items中定义字段名用于校验解析数据字典的key是否准确。
1 2 3 4 5 6 7 8 9 10 class BookItem (scrapy.Item): """ items文件主要用于字段校验 """ title = scrapy.Field() price = scrapy.Field() author = scrapy.Field() date_data = scrapy.Field() detail = scrapy.Field() producer = scrapy.Field()
在爬虫文件中导入定义的items类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class BookInfoSpider (scrapy.Spider): name = "book_info" start_urls = ["http://xxx.com/" ] def parse (self, response: HtmlResponse, **kwargs ): li_list = response.xpath('//ul[@class="bigimg"]/li' ) for li in li_list: item = BookItem() item['title' ] = li.xpath('./a/@title' ).extract_first() item['price' ] = li.xpath('./p[@class="price"]/span[1]/text()' ).extract_first() item['author' ] = li.xpath('./p[@class="search_book_author"]/span[1]/a[1]/@title' ).extract_first() item['date_data' ] = li.xpath('./p[@class="search_book_author"]/span[last()-1]/text()' ).extract_first() item['detail' ] = li.xpath('./p[@class="detail"]/text()' ).extract_first() if li.xpath( './p[@class="detail"]/text()' ) else '空' item['producer' ] = li.xpath( './p[@class="search_book_author"]/span[last()]/a/text()' ).extract_first() if li.xpath( './p[@class="search_book_author"]/span[last()]/a/text()' ) else '空' yield item
当我们定义字典的key时,没有按照items声明的key进行定义则会抛出异常